판다스의 데이터 프레임을 요리하는 방법을 정리하는 중이다.
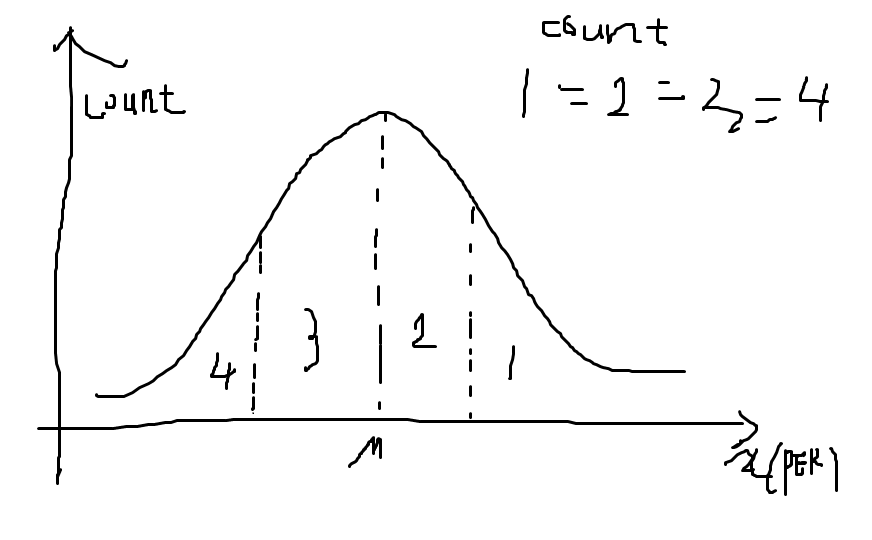
정규 분포에서 1 영역과 2 영역과 3 영역과 4 영역의 Count 수, 즉 면적이 모두 같게끔 Grouping을 하는 방법에 대해서 알아보자.
현재 Read 한 데이터 프레임은 아래와 같다.

이 데이터 프레임을 PER 칼럼을 기준으로 3 영역으로 나누어 보도록 하겠다.
판다스에서 제공해 주는 qcut이라는 함수를 이용하면 된다.
데이터프레임과 영역을 인자값으로 넘겨주었다.

그럼 인덱스에 따라 category라는 타입 형태로 3가지가 생겼다.
+ (7.666, 16.495]
+ (16.495, 7056.129]
+ (-27857.497, 7.666]
그런데 타입 형태가 매우 직관적이지 않으므로 직관적인 형태로 변경해 보자.
아래와 같이 labels = [1,2,3]으로 group 이름을 정해주었다.

그럼 이제 데이터 개수를 기준으로 group을 나눈 시리즈를 데이터프레임 자료에 추가하는 것을 알아보겠다.
loc을 사용하여 PER_Score2라는 칼럼을 추가하여 앞에서 만든 데이터 시리즈 형태의 자료를 넣어주면 된다.
df.loc[:, 'PER_Score2'] = pd.qcut(df['PER(배)'] , 3, labels=range(1,4))

그럼 value_counts() 함수를 이용해 PER_Score2 칼럼의 데이터의 개수가 균등하게 나누어졌는지 확인해 보면 223개로 균등하게 나누어진 것을 확인할 수 있다.

그런데 항상 NaN 값이 있는지 살펴보는 습관을 가져야 한다. 데이터의 왜곡을 줄 수 있기 때문이다.
hasnans를 이용해 살펴본 결과 True 이므로 NaN값을 갖고 있고
isna() 함수로 boolean Series 데이터를 만들어서 NaN값이 있으면 True 없으면 False로 만들고 sum()을 통해 Series 데이터를 더한 값을 출력한다.
12로 12개의 NaN값을 가지고 있는 것을 확인했다.

여기서는 NaN값을 가지고 있는 row를 삭제하는 방법으로 정리해 보겠다.
df.dropna(subset = ['PER(배)'])를 이용하여 df에 다시 넣어 주었다.
PER(배)라는 칼럼의 NaN값이 있으면 그 row값을 다 삭제하는 함수이다.

df['PER_Scroe2'].isna().sum() 의 출력값이 12에서 0으로 바뀐 것을 확인할 수 있다.
'백테스트를 위한 파이썬' 카테고리의 다른 글
| FinanceDataReader에서 주가 데이터 연산하기 (0) | 2023.12.04 |
|---|

댓글